本資料は2020年8月28日に社内共有資料として展開していたものをWEBページ向けにリニューアルした内容になります。
■Purpose
Purpose of this material
- Understand an anchor free approach object detection algorithm
■Agenda
- Current object detection approaches
- Centernet approach
- Object as Points
- Training
- Keypoint heatmap
- Local offset
- Size prediction
- Loss function
- Network Architecture
- DLA
- Modified DLA
- Inference
- Results
■Background
Current approaches
- Object detections model (such as Yolo, SSD, etc.) rely on the usage of anchor boxes
- Anchor boxes are not completely optimal:
- Wasteful: SSD300 does 8732 detections per class, and yolo448 does 98 detections per class, which means that most of the box are discarded
- Inefficient: We have to process all the boxes (even we will discard them later), which comes with more processing time
- Require post processing: like non-max suppression algorithm
- Fixed: SSD requires fixed scale and steps of boxes, while yolov3 fixes the size of the anchors per detection level
■Centernet
Centernet approach
- End-to-end differentiable solution
- Relies on keypoint estimation to find the center points and regress all other object properties(such as size)
- As a result, the model is simpler, faster and more accurate than bounding-box based detectors
■Object as Points

■Training

■Keypoint Heatmap



■Local Offset


■Size Prediction

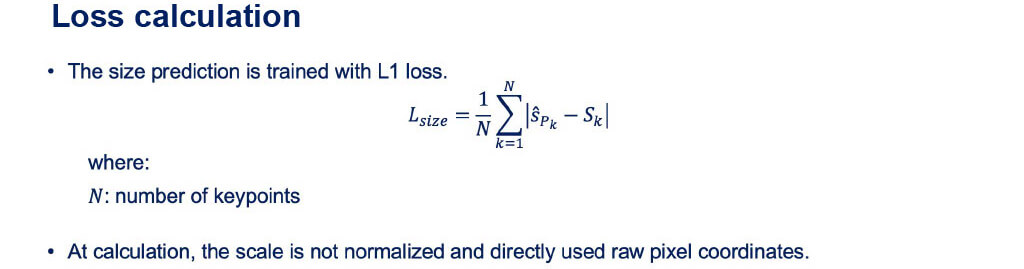
■Loss Function
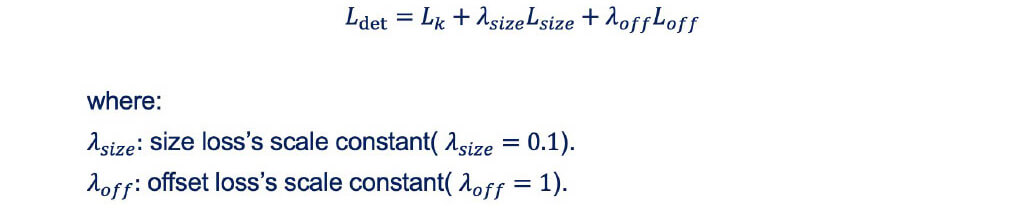
■Network Architecture
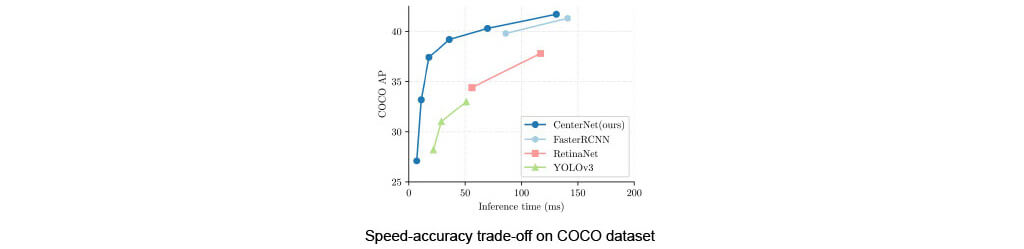
- Authors experiment with different backbone architectures, obtaining different results:

Results without test augmentation(N.A.), flip testing(F), and multi-scale augmentation(MS). HW: Intel Core i7-8086k CPU, Titan Xp GPU
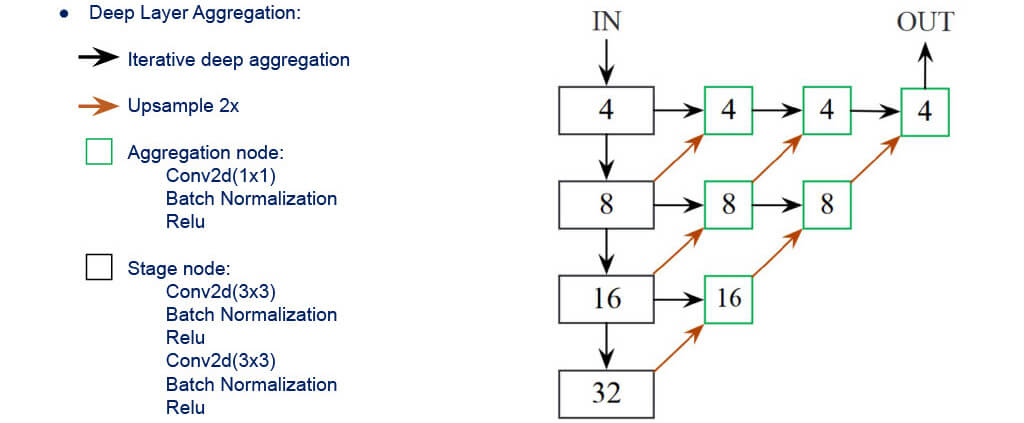
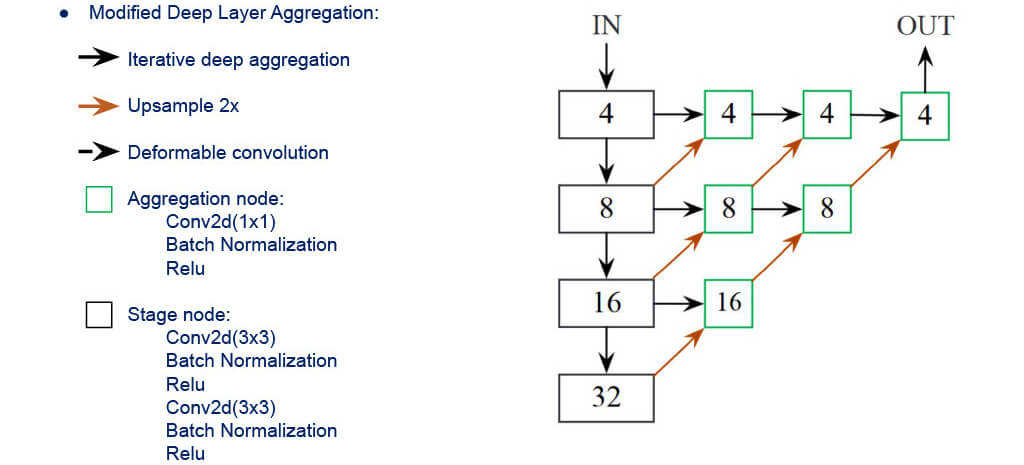
- The backbone that produces best speed/accuracy tradeoff is DLA-34 (modified by authors)
■Network Architecture
■Inference

■Results