本資料は2020年08月21日に社内共有資料として展開していたものをWEBページ向けにリニューアルした内容になります。
■目次と内容
目次
- Dialogue State Trackingタスクの評価方法について
- Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems, 2019
- SAS: Dialogue State Tracking via Slot Attention and Slot Information Sharing, 2020
- A Contextual Hierarchical Attention Network with Adaptive Objective for Dialogue State Tracking, 2020
内容
- 最新の対話システム(特にタスク指向)研究について発表
- 事前に関連技術に関しての知識がない方でも分かりやすいように説明多め
- 最近のモデルのスタンダードになっているACL2019の論文1本,ACL2020の論文を2本紹介
■Dialogue State Trackingタスクの評価方法
Task-Oriented Dialogueの例
最終的な目標が存在する対話

Task-oriented dialogueにおけるPipeline手法[1]
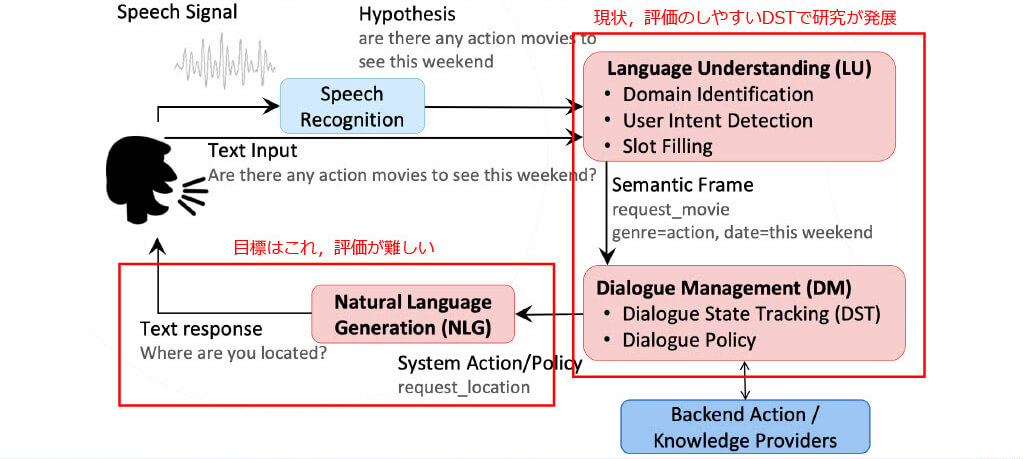
Dialogue State Tracking (DST)
対話をする上で記憶すべき単語を抜き出すするタスク

MultiDomain Wizard-of-Oz dataset (MultiWOZ)[2]
人と人の対話を人手でアノテーションしたDST評価データセット

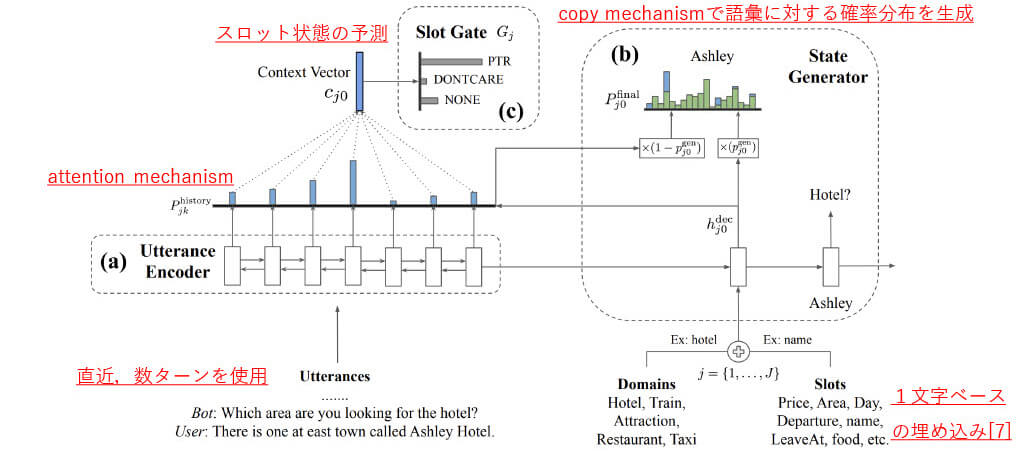
■TRAnsferable Dialogue statE generator(TRADE)[3]

新規性
- ドメイン名・スロット名を入力として扱う
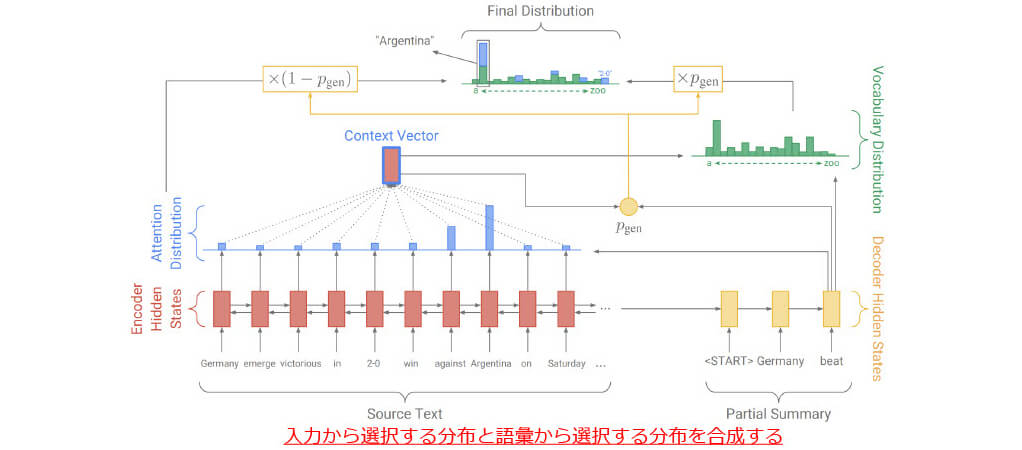
- copy機構を利用した語彙出力でスロット値を予測
- スロット値の状態も予測し,スロット値予測と同時に最適化
- few-shot,zero-shotの問題に対する精度も調査
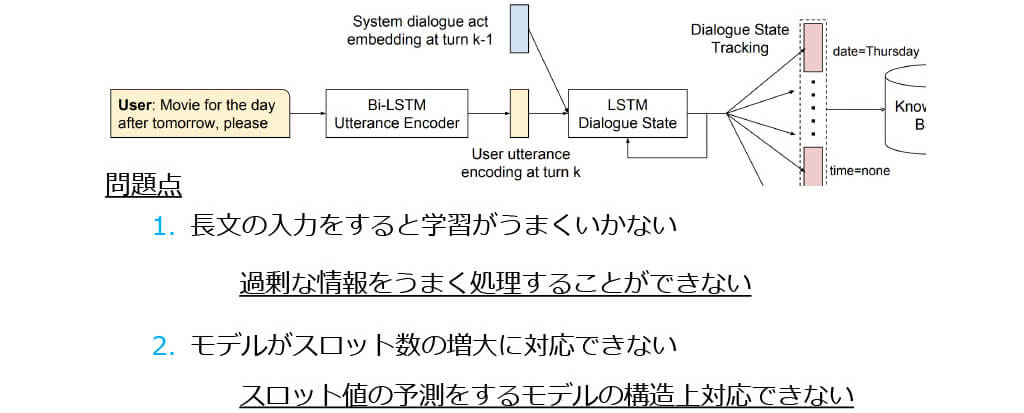
■TRADE: 従来の手法[4]の問題点
■TRADE:モデル概要

■Copy mechanism : index-based[5]

■Copy mechanism : soft-gated copy[6]
■TRADE:モデル概要(再掲)
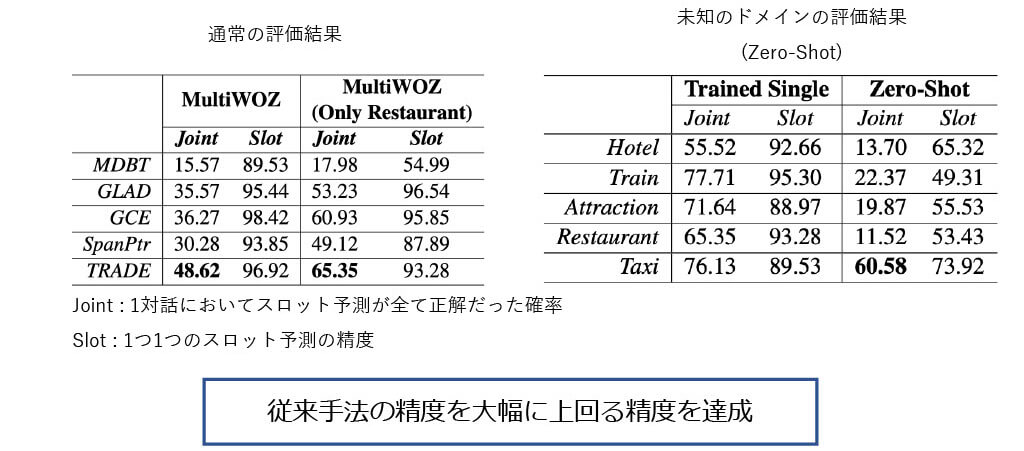
■TRADE:評価実験(通常,Zero-Shot)
■TRADE: Few-Shot問題に対する適用方法

■TRADE: Few-Shot問題の評価実験

1行目:学習するドメインの種類(全5ドメインの内1ドメインをFew-shotと仮定)
2行目:全データが普通に入手できる時の精度(予測精度の上限)
3行目:1%ドメインで学習後の,事前学習した4ドメインの精度
5行目:1%ドメインのみで学習した精度
■TRADE: まとめ
- Attention機構、Copy機構を利用した長文の入力から効率良く情報を抽 出できるDSTモデルを提案
- ドメイン名・スロット名を入力として扱うことで、 従来のスロット数増加 問題を解決
- MultiWOZタスクにおいて従来手法の結果を大幅に超えるDST精度を示した
- データが入手できない,少量しか入手できない場合の問題設定を提起し、 提案手法を用いた予測精度ベンチマークを示した
■Slot Attention and Slot information sharing(SAS)[8]

新規性
- 入力の各スロットに必要な情報をSlot Attentionで重み付け
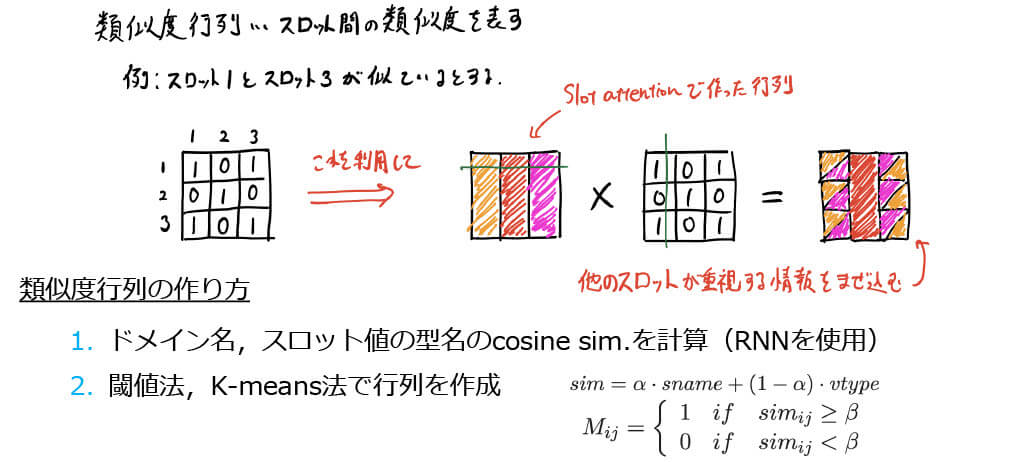
- 事前に作成したスロット間の類似行列を用いてスロット間の情報を共有
■SAS: TRADEの問題点
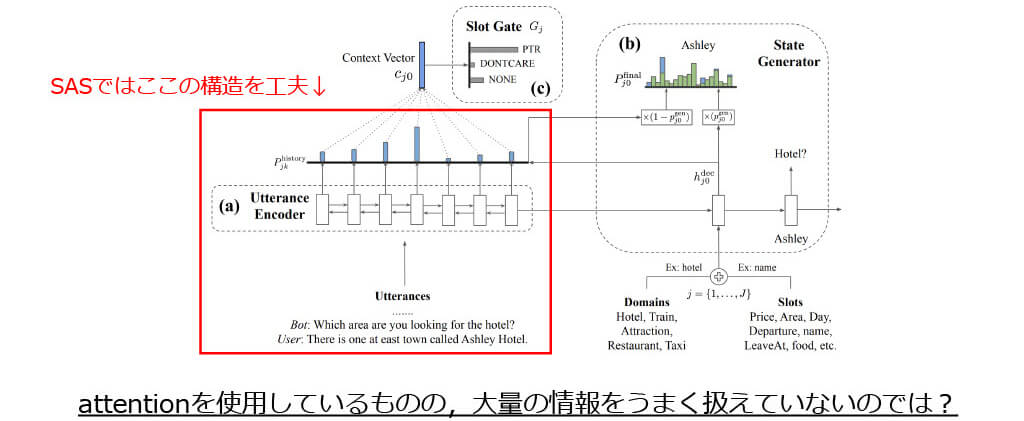
■SAS: モデル概要
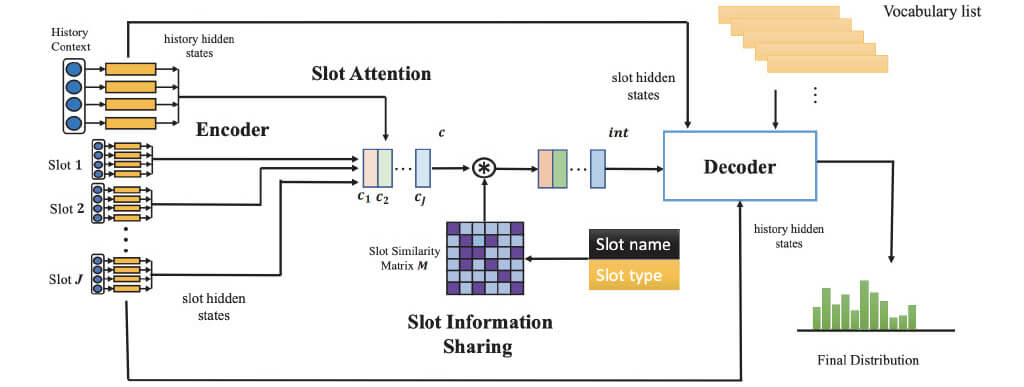
■SAS: Slot Attention

■SAS: Slot Information Sharing
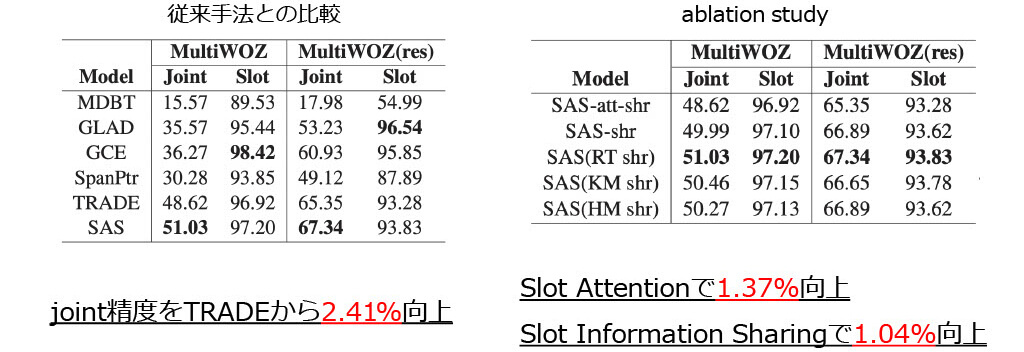
■SAS: 評価実験
■SAS: まとめ
まとめ
- 情報過多な入力をうまく扱うために対話ターン毎にAttentionするSlot Attentionとスロット間で情報を共有するSlot Information Sharingを提案
- MultiWOZにおいて,TRADEをjoint精度で2.43%上回る精度を示した
感想
- Slot Information Sharingは結局のところAttentionなのでは?
(Attentionとして扱った方がパラメータ自動推定されるし…) - 明示的にSlot Information Sharingするのかスロット名を embeddingして上手く情報を共有してくれるのを期待した方がいいのかは,もう少し慎重に調べる必要がある
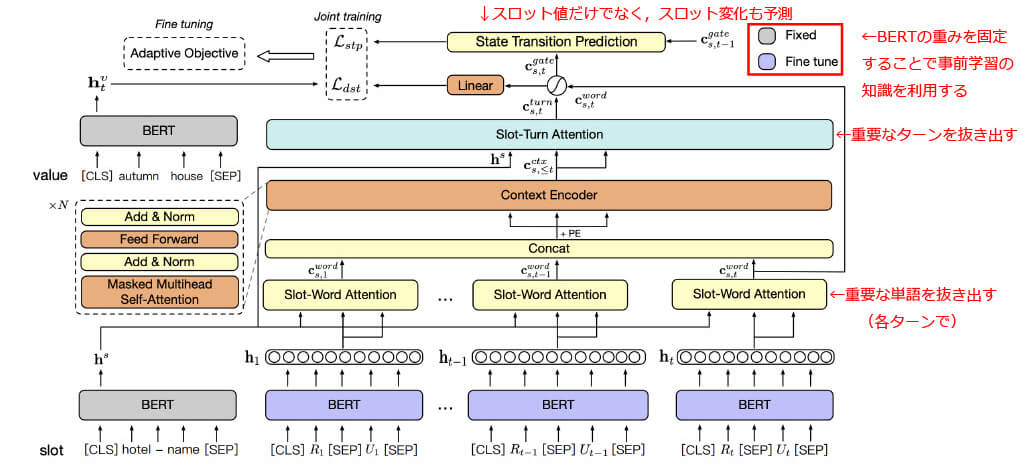
■Contextual Hierarchical Attention Network (CHAN)[9]

新規性
- 階層的な単語レベル,ターンレベルのAttention構造で効率的に入力を変換
- 重みをfixした事前学習BERTを利用することで,データセット外の知識を利用
- 適応的誤差を利用することで,予測が難しいスロットの学習を促進
■CHAN:モデル概要
■SAS: エンコーダ部分の計算
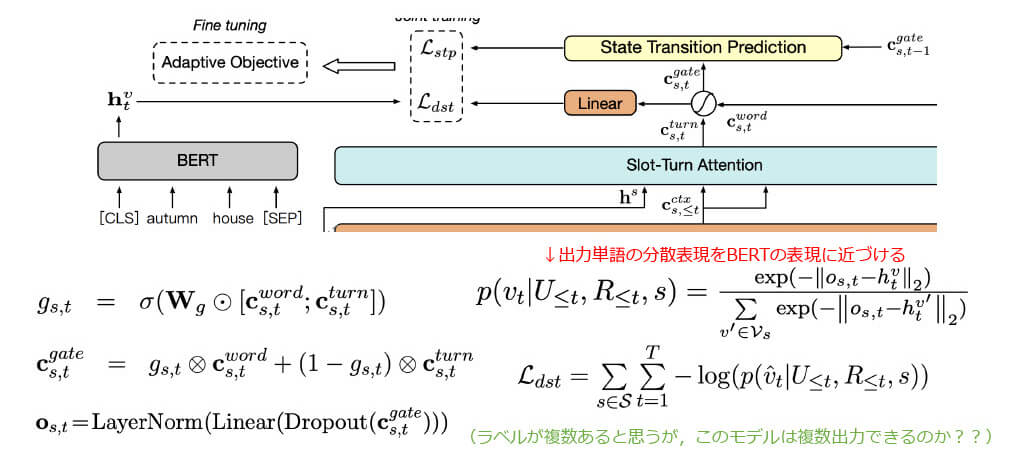
■CHAN:適応的誤差 (Adaptive Objective)

■CHAN: 評価実験
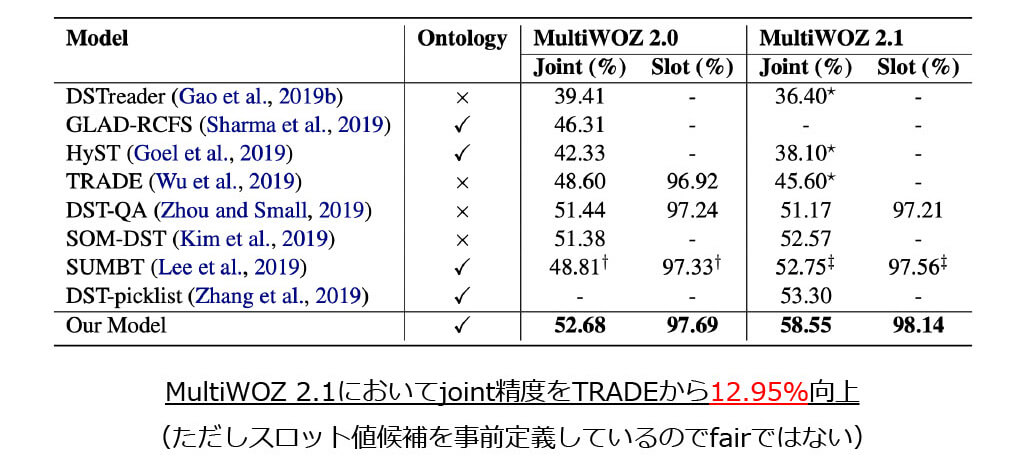
■CHAN: Abulation Study

■CHAN: Visualization of Attention

■CHAN: まとめ
- 単語とターンレベルのAttention,Transformer型の中間層,そして事前 学習モデルのBERTを利用したDST予測モデルを提案
- また,学習を促進させるためにスロット変化を予測する副タスクも同時 に最適化し,スロット間の不均衡問題を解消するために適応的誤差を利用
- MultiWOZにおいて,従来手法を大きく上回る結果を示した
- MultiWOZ2.0 : TRADE + 4.08%
- MultiWOZ2.1 : TRADE + 12.95%
■参考文献


