本資料は2020年12月15日に社内共有資料として展開していたものを WEBページ向けにリニューアルした内容になります。
■Purpose
Purpose of this material
- Explore a solution to the task of video summarization using attention.
■Agenda
- Introduction
- Motivation
- Contributions
- Dataset
- VASNet
- Feature Extraction
- Attention Network
- Regressor Network
- Inference
- Changepoint Detection
- Kernel Temporal Segmentation
- Results
- Measuring method
- Dataset Results
■Introduction
Motivation
- Early video summarization methods were based on unsupervised methods,leveraging low level spatio-temporal features and dimensionality reduction with clustering techniques.Success of these methods solely stands on the ability to define distance/cost functions between the keyshots/frames with respect to the original video.
- Current state of the art methods for video summarization are based on recurrent encoder-decoder architectures, usually with bidirectional LSTM or GRU and soft attention. They are computationally demanding, especially in the bi-directional configuration.
Contribution
- A novel approach to sequence to sequence transformation for video summarization based on soft, self-attention mechanism. In contrast, current state of the art relies on complex LSTM/GRU encoder-decoder methods.
- A demonstration that a recurrent network can be successfully replaced with simpler, attention mechanism for the video summarization.
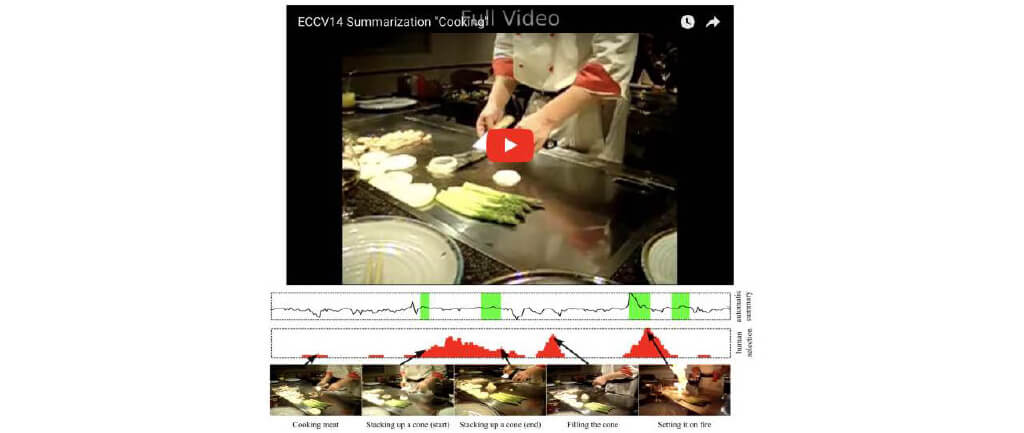
■Dataset
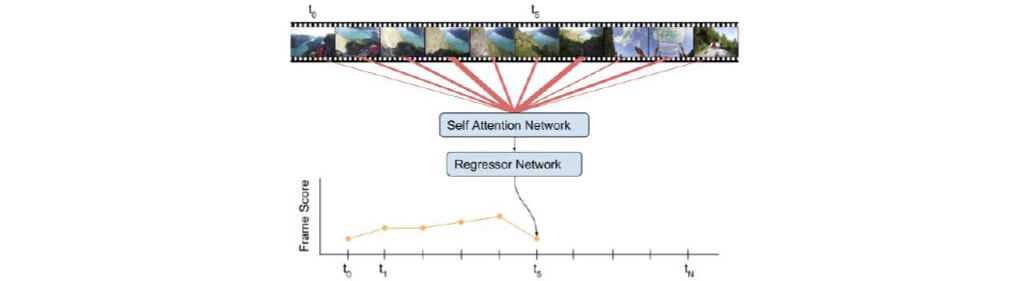
■VASNet
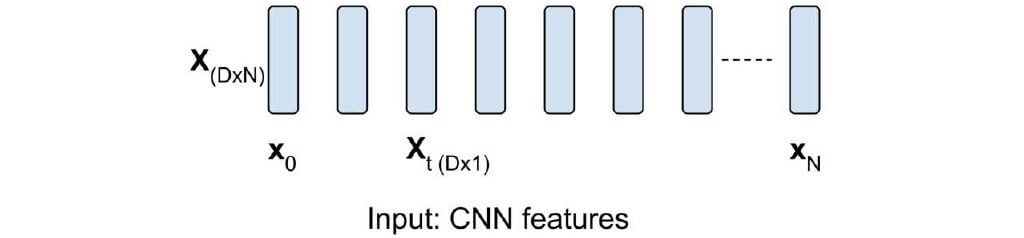
Feature Extraction
- Given a time interval t, every 15 frames are collected in an ordered set X
- Each set then is used as input to GoogLeNet for feature extraction
- hen we extract the Pool 5 layer of GoogLeNet, which is a 1024 dimensional array (D = 1024).
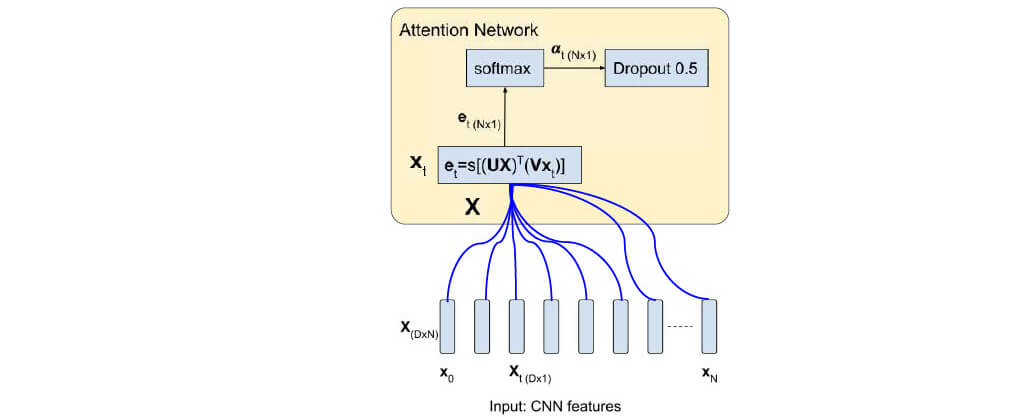
Attention Network

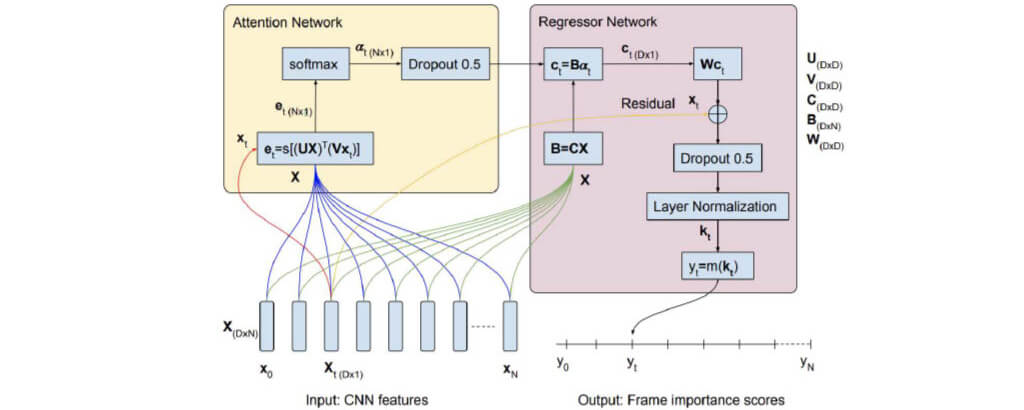
Regressor Network

■Inference
- The output of the model VASNet is a probability of importance per frame
- This probability must be analyzed in the range of the scene it corresponds
- However to get the number of frames is relative per video
- The problem to find the frames where a change a scene exist is called changepoint detection.
- For the datasets used, the changepoints (cps) are already calculated by using KTS algorithm with hyperparameter tuning

Changepoint detection
- In statistical analysis, change detection or change point detection tries to identify times when the probability distribution of a stochastic process or time series changes. In general the problem concerns both detecting whether or not a change has occurred, or whether several changes might have occurred, and identifying the times of any such changes.
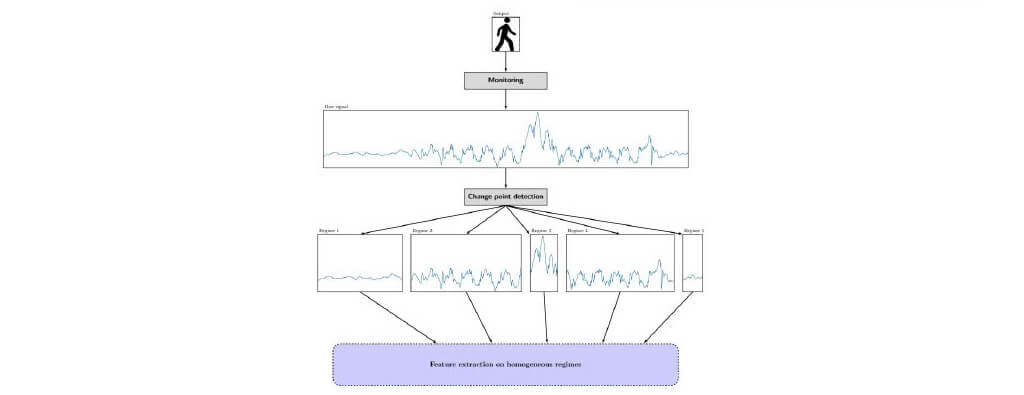
Kernel Temporal Segmentation (KTS)
- Kernel Temporal Segmentation (KTS) method splits the video into a set of non-intersecting temporal segments.
- It treats the cps detection as a dynamic programming problem.
- The method is fast and accurate when combined with highdimensional descriptors.

■Results
Measuring method
P: Precision
R: Recall
F Score: [2 * P * R / (P + R)] * 100

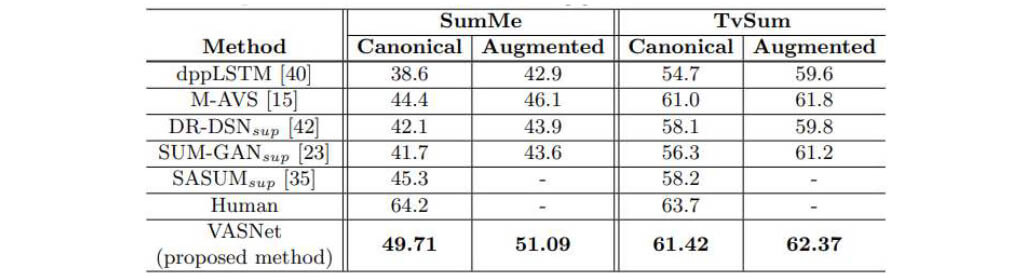
Dataset Results
■References
- VASNet: https://arxiv.org/pdf/1812.01969.pdf
- VASNet official implementation: https://github.com/ok1zjf/VASNet
- KTS implementation: https://github.com/TatsuyaShirakawa/KTS
- Video summarization datasets and review: https://hal.inria.fr/hal-01022967/PDF/video_summarization.pdf
- Issue on testing on own videos: https://github.com/ok1zjf/VASNet/issues/2