本資料は2021年04月13日に社内共有資料として展開していたものをWEBページ向けにリニューアルした内容になります。
■目次
・Transformerの概要
・Transformerの各構造解説
- Positional Encoding
- Attention
- Multi-headed Scaled Dot-Product Self-Attetion
- Shortcut Connection, Layer Normalization, Position-wise Feedforward Network
- Transformerの実験結果・考察
■[概要] Transformerって何?
2017年の論文Attention Is All You Need[1]で発表されたモデル
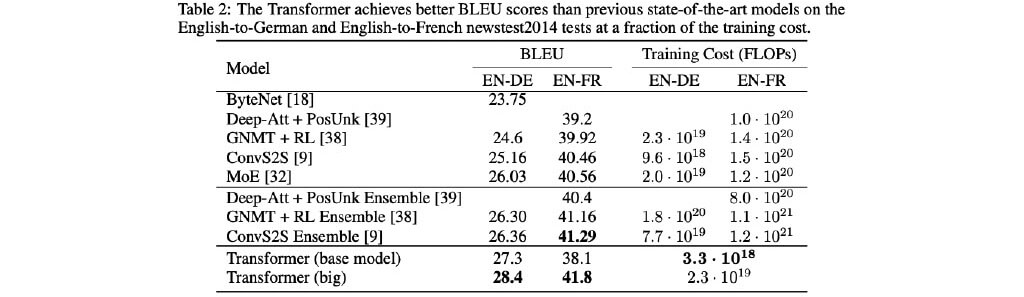
機械翻訳タスクにおいて既存SOTAよりも高いスコアを記録
[1] Vaswani, Ashish et al. “Attention is All you Need.” ArXiv abs/1706.03762 (2017)
■[概要] Transformerの他分野への応用
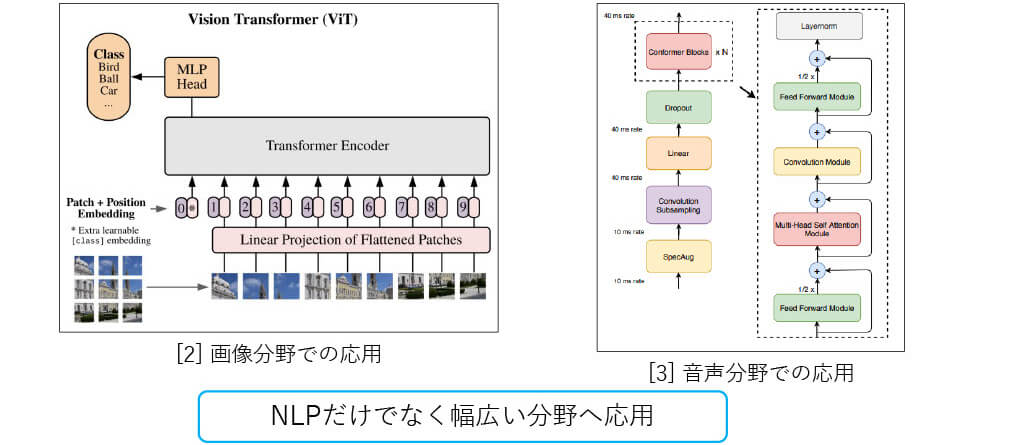
[2] Dosovitskiy, A. et al. “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale.” ArXiv abs/2010.11929 (2020)
[3] Gulati, Anmol et al. “Conformer: Convolution-augmented Transformer for Speech Recognition.” ArXiv abs/2005.08100 (2020)
■[概要] NLPにおけるモデルの発展
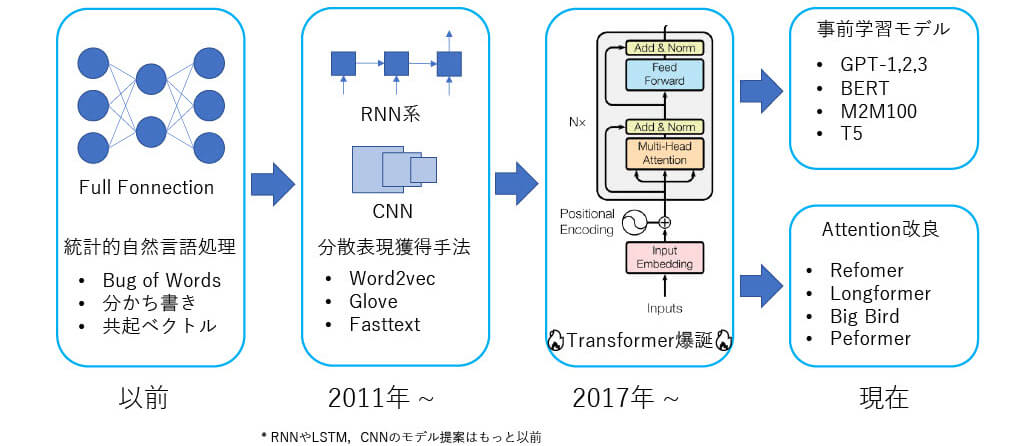
■[概要] RNN, CNN vs Transfomer
Recurrent Neural Network (RNN)

Convolutional Neural Network (CNN)

Transformer

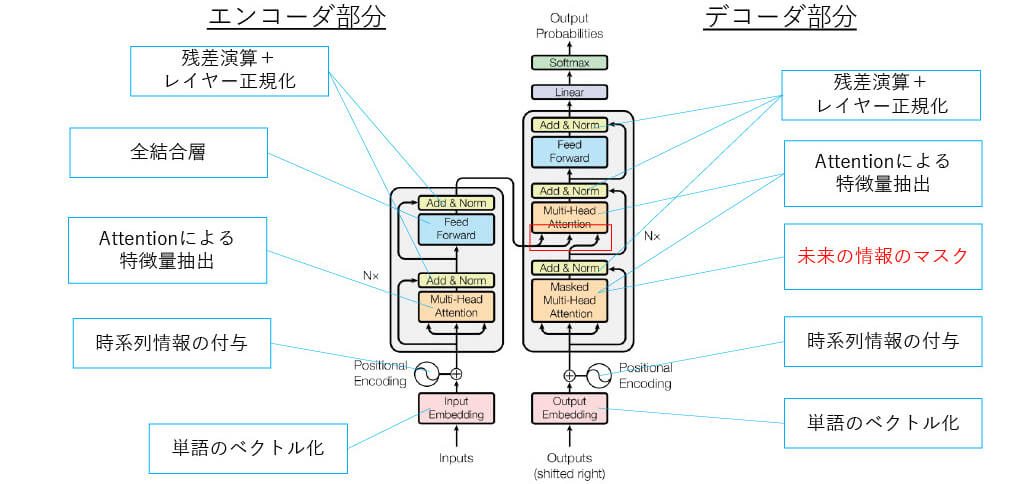
■[構造解説] Transformerの全体図
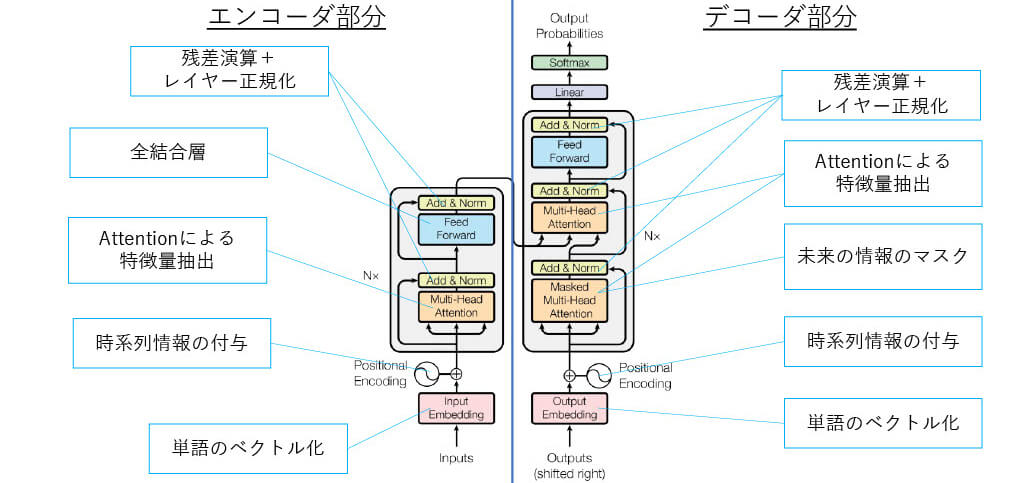
■[構造解説】Positional Encoding(1)
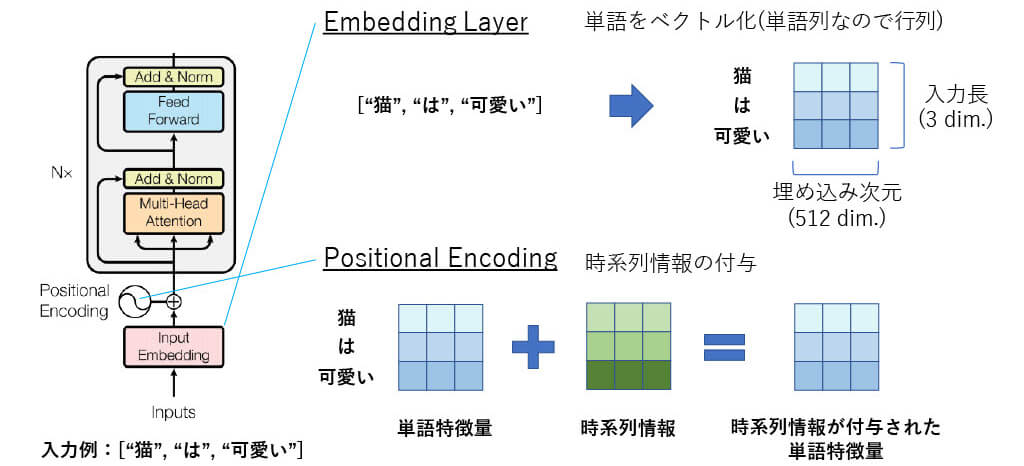
■[構造解説] Positional Encoding(2)

■[構造解説] Positional Encoding(3)

[4] http://jalammar.github.io/illustrated-transformer より
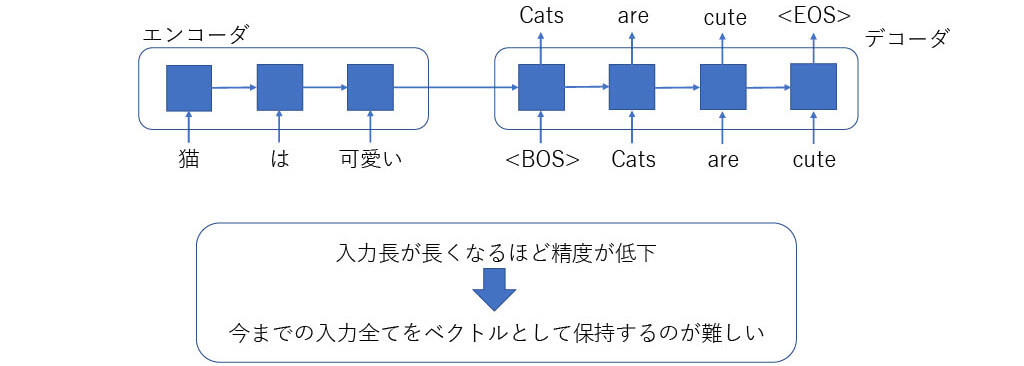
■[構造解説] Attention機構(1)
従来のSeq2Seq型のRNN翻訳モデル
■[構造解説] Attention機構(2)
Attentionを利用したSeq2Seq型のRNN翻訳モデル

■[構造解説] Attention機構(3)
Attention計算式(dot product attention)

■[構造解説] Attention機構(4)
Attentionを利用したSeq2Seq型のRNN翻訳モデル
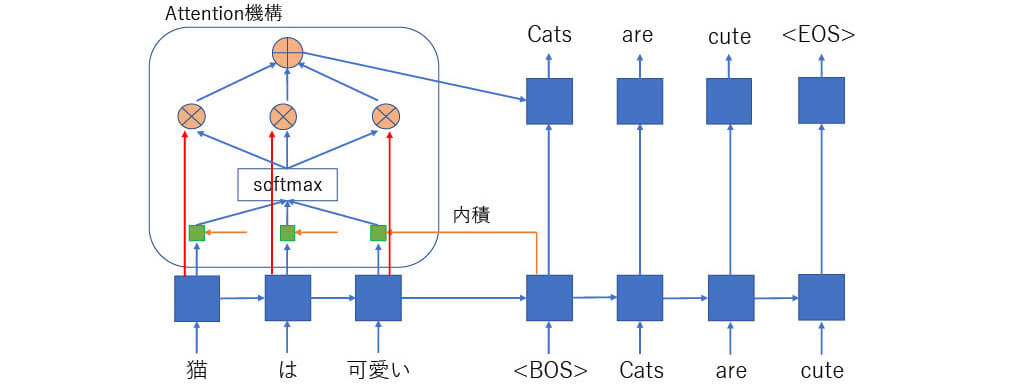
■[構造解説] TransformerのAttention

■[構造解説] Self -Attention
Query, Key, Valueが全て同じAttention
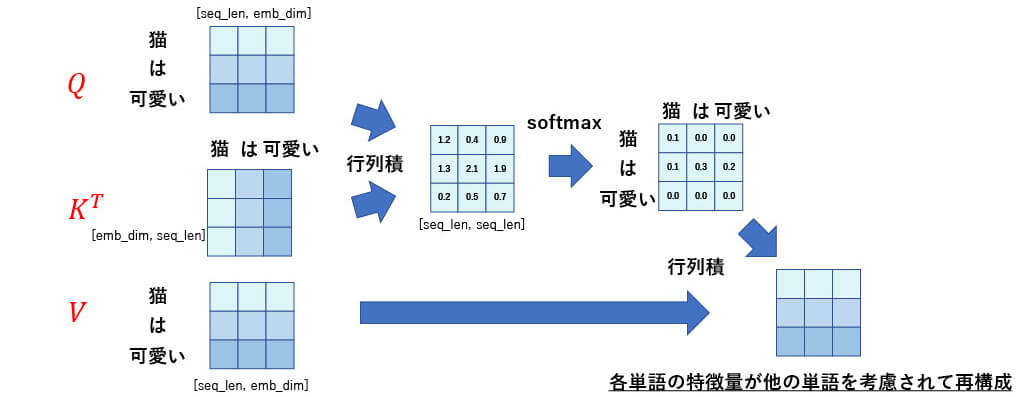
■[構造解説] Scaled Dot-Product Attention

■[構造解説] Multi -Head Attention(1)

■[構造解説] Multi -Head Attention(2)
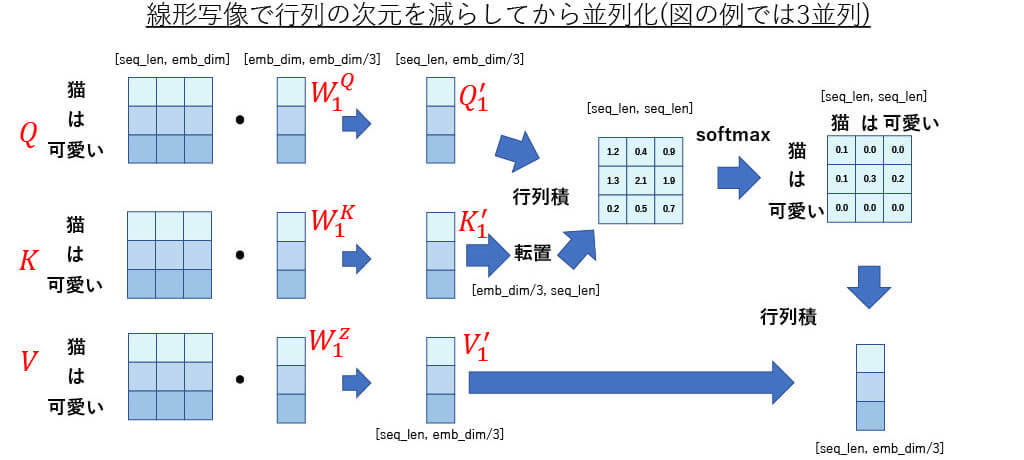
■[構造解説] Multi -Head Attention(3)
線形写像で行列の次元を減らしてから並列化(図の例では3並列)
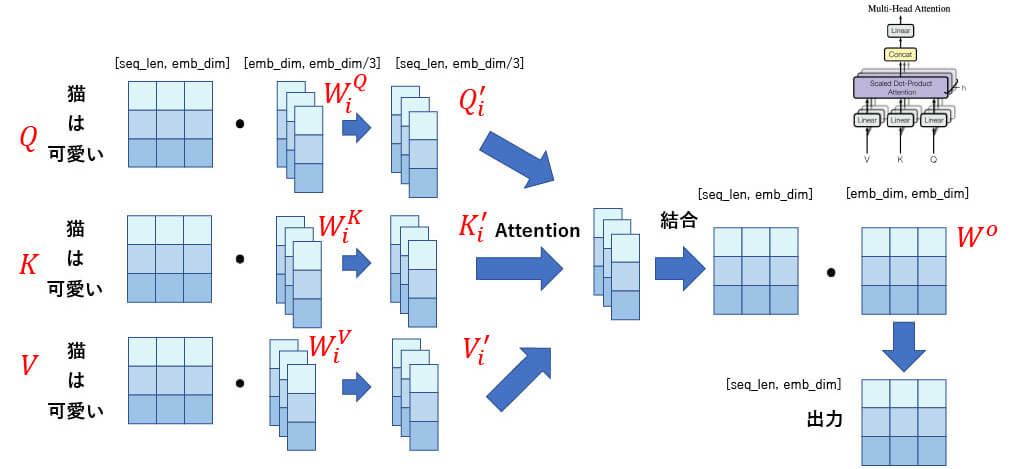
■[構造解説] Multi -Head Attention(4)
数式

なぜMulti-Headなのか?
- Attentionする空間を選択でき、限定された特徴量空間でAttentionできる
- 単一Attentionでは平均的なAttentionとなる(大雑把なAttention)
- そして,単語の要素は1つではないのでMultiが望ましい(単語意味,品詞)

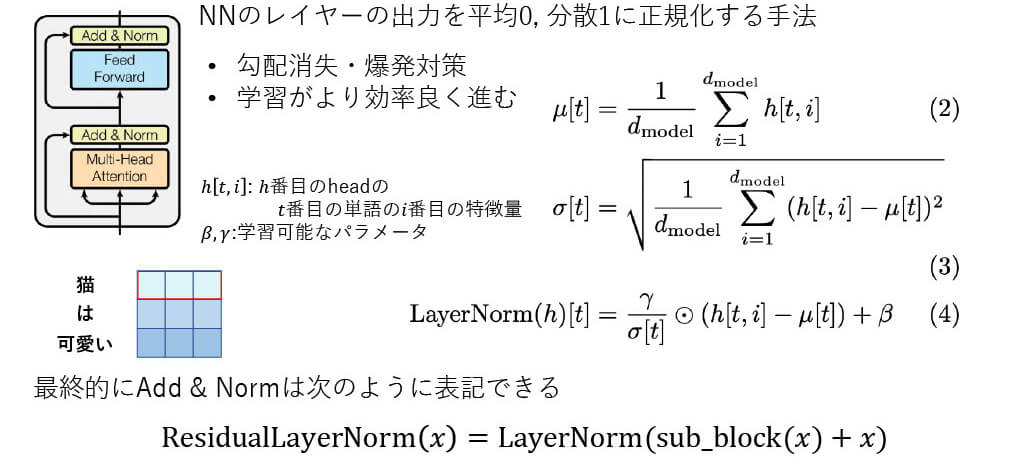
■[構造解説] Shortcut Connection
2015年に提案されたResidual Network(ResNet)[4]の要素

[4] He, Kaiming et al. “Deep Residual Learning for Image Recognition.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016).
■[構造解説] Layer Normalization
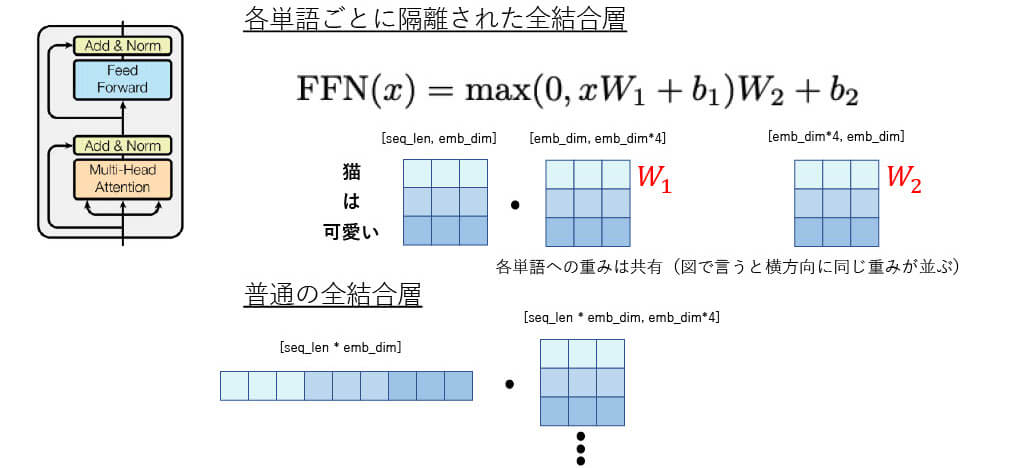
■[構造解説] Position-wise Feed-Forward Networks
■[構造解説] Transformer Moduleのまとめ

■[構造解説] Transformerの全体図(再掲)
■[構造解説] RNN系の推論方法
従来のSeq2Seq型のRNN翻訳モデル

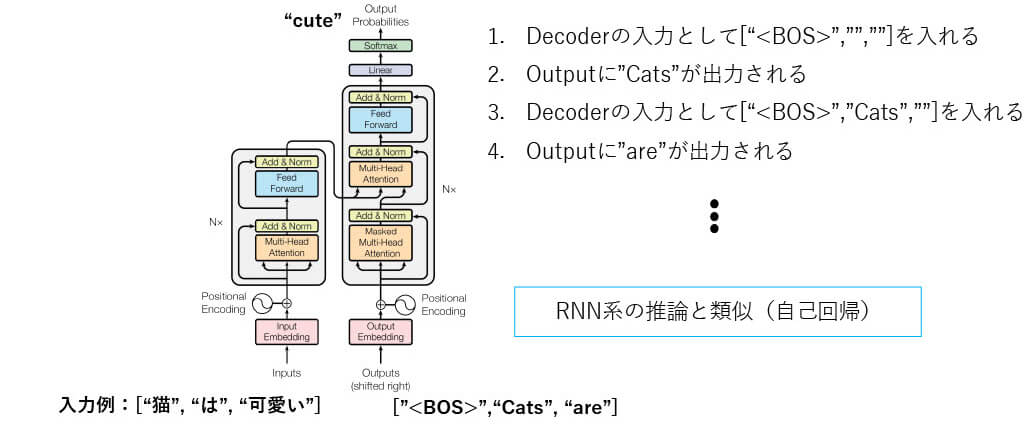
出力されたものをデコーダの入力に再度入力して得ていく
■[構造解説] Transformer Decoderの推論(イメージ)
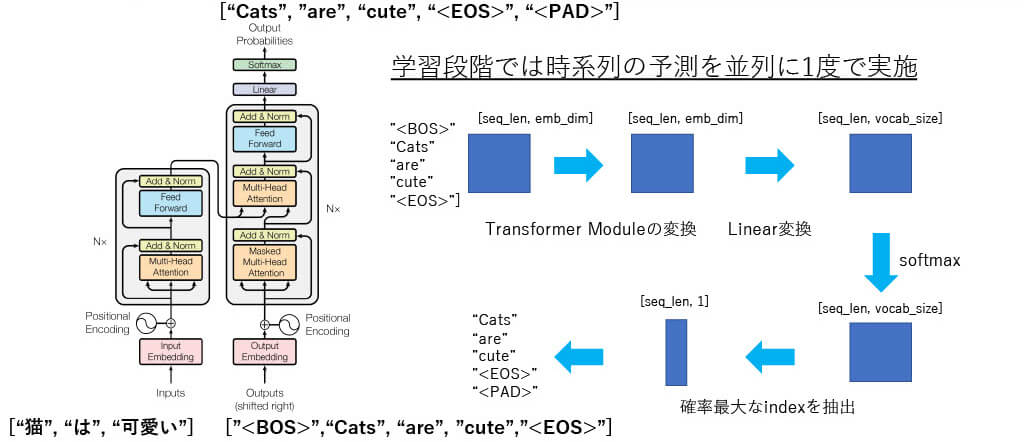
■[構造解説] Transformer Decoderの学習
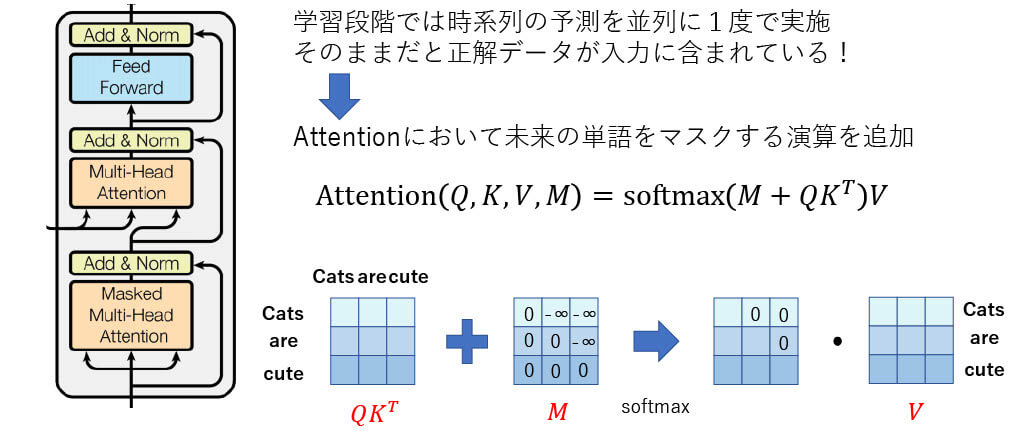
■[構造解説] Masked Attention
■[実験結果] 機械翻訳タスクの実験結果
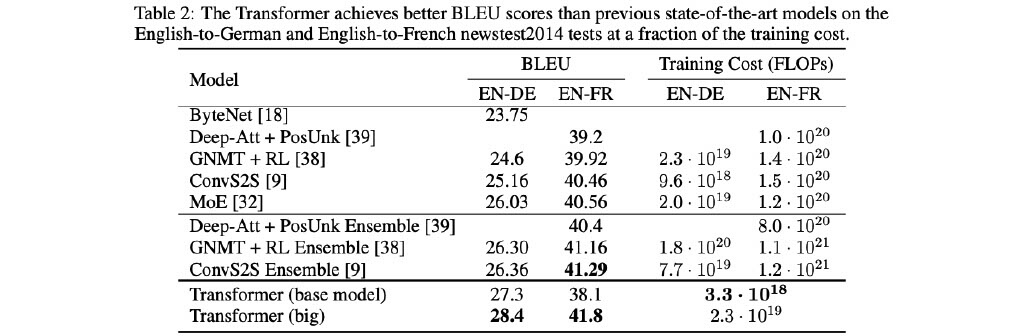
既存の手法よりも高いスコア & 学習コストも
[1] Vaswani, Ashish et al. “Attention is All you Need.” ArXiv abs/1706.03762 (2017)
■[実験結果] Self -Attentionの計算量

- 𝑛 < 𝑑の場合は,Self-Attentionの計算量はRNNよりも小さくなる
- RNNは前の値を待つ必要があるので計算時間はよりかかる
- Self-Attentionは長期の依存関係を学習しやすい
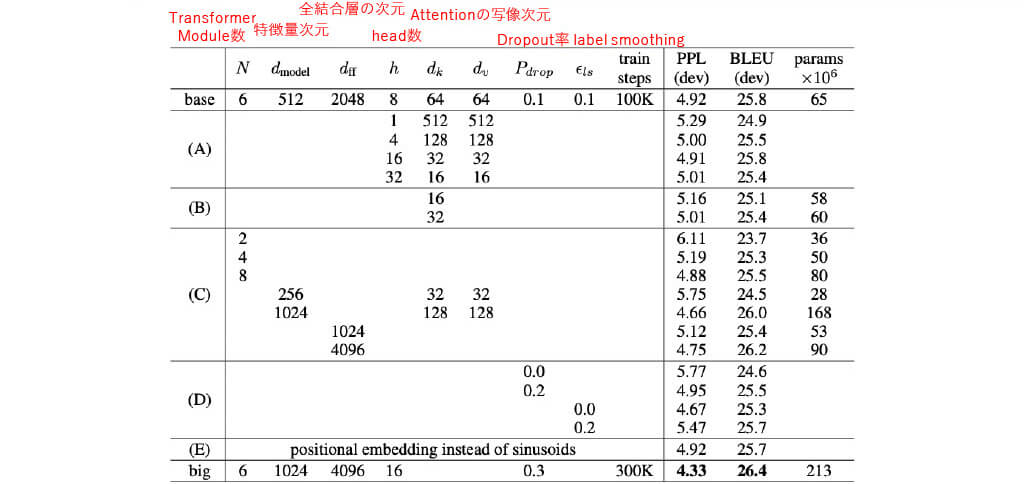
■[実験結果] 各パラメータの精度への影響
■Transformerまとめ
1.TransformerはAttentionベース構造で計算量・GPU親和性が高いモデル
2.時系列データを一度に処理するためPositional Encodingを実施する必要
3.TransformerのAttentionは以下の要素を持つ
- Self-Attention(入力同士を用いて特徴量を再構築)
- Scaled Dot-Product Attention(勾配情報を保持しつつ内積する)
- Multi-Headed Attention(複数のヘッドを用いて並列にAttention)
4.デコーダでは未来の情報のリークを防ぐためにMasked Attentionする
5.実験結果からTransformerの高性能,低計算量が示された

