本資料は2020年10月29日に社内共有資料として展開していたものをWEBページ向けにリニューアルした内容になります。
■Instance Segmentation
➔ “Instance segmentation is the task of detecting and delineating each distinct object of interest appearing in an image” — source
➔ Sub-task of:
- “Object Detection”
- “Semantic Segmentation”
➔Improvements in baselines (R-CNN, FCN) for the “parent” tasks do not automatically apply to the “daughter” task
➔ Typically combines:
- detection of boxes for all objects
- segmentation of pixels
■Methodology
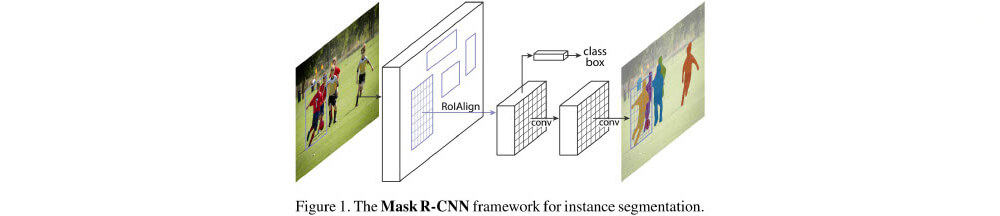
➔ Based on the Mask R-CNN model:
- Approach is “detect” and THEN “segment”: two-steps
- A Region-based CNN (Faster R-CNN)
outputs class labels and bounding-box offset for each candidate- Start with a Region Proposal Network (RPN)
- Extract features from RoI and predict class and bbox
- Additionally adds a branch to output the pixel mask of the object
- Uses Fully Convolutional Networks (FCN) sharing weights and maintaining spatial correspondence
- Needs alignment between pixels and feature maps (RoIAlign)

➔ Based on the YOLACT model:
- Approach is single-step, like anchor-free object detection (e.g. CenterNet) (but still has anchors)
- Uses a “global mask” instead of separate masks for instances: no loss of quality due to reduced resolution
- Performs 2 parallel tasks:
- Generate prototype “global” masks (entire image)
- Predict linear combination of coefficients for each instance (hence the name: You Only Look At CoefficienTs)
- Instance masks are constructed by combining prototypes with the learned coefficients in an assembly step (crop to bbox)
- Computation cost is constant with #instance


■Related work
YOLACT (and YOLACT++) are similar to:
- BlendMask (CVPR20) uses attention maps instead of coefficients
- CenterMask (CVPR20) based on anchor-free Obj. Detection
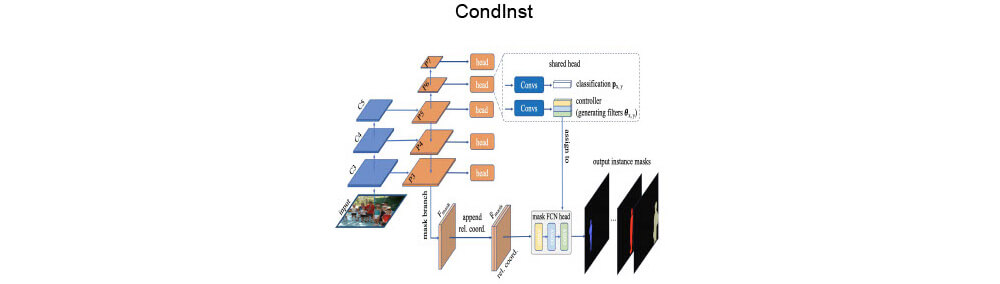
- CondInst removes dependency on bbox in assembly step
- SOLO and SOLOv2 entirely bbox free: predicts instance category directly pixel by pixel
Exceptional resources on the open-source instance-segmentation toolbox from Adelaide University (on top of detectron2): AdelaiDet
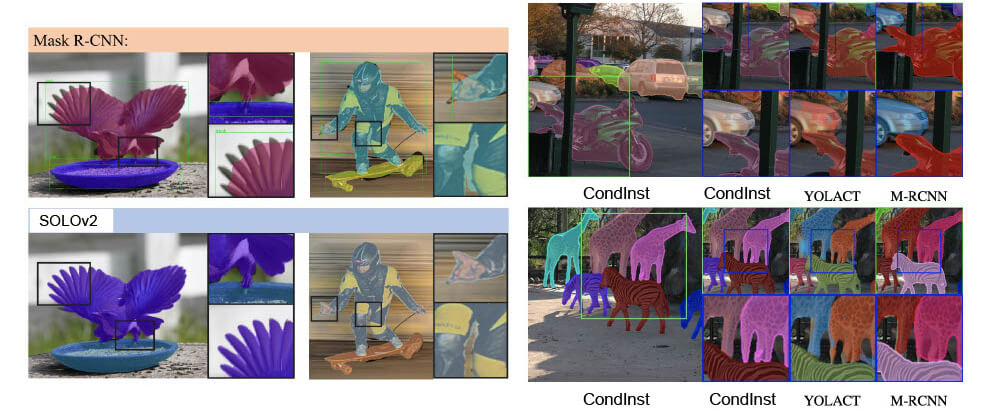
Mask accuracy details
■Real-time instance segmentation


■More Real-Time instance segmentation