本資料は2020年7月2日に社内共有資料として展開していたものをWEBページ向けにリニューアルした内容になります。
■Agenda
Introduction
- Image Segmentation
- Problems
- Self-supervised learning
- Content of this presentation
Survey
- Pseudo Labeling
- Class Activation Map
- Image Depth Information
- How about using videos
Some comments
■Image Segmentation

■Problems

- very hard to annotate (=expensive)
- pixel-wise annotation
- different types of objects
- boundaries are often blurry
- easy to make mistake
- lots of unclear cases
- Need to keep focus for long time
How can we change this situation?
■Self-supervised learning
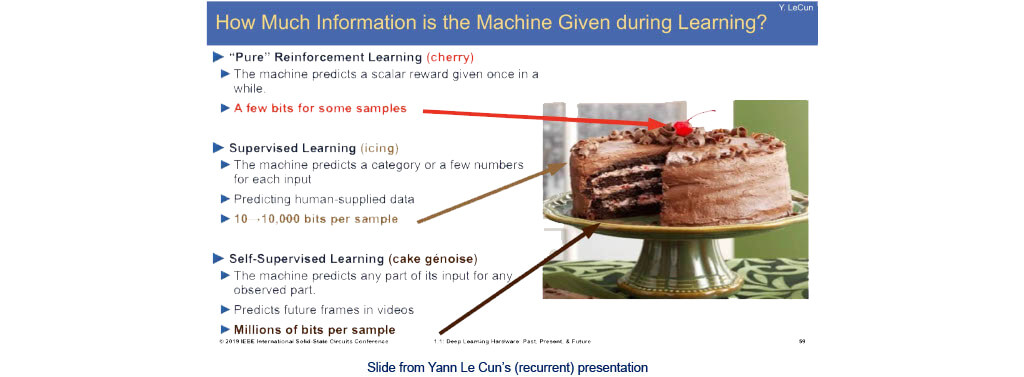
- Research topic pushed by “godfathers of AI” and specially by Yann Le Cun
- Pre-train a feature extractor in an unsupervised way then train the classifier with annotated data
- Reach SOTA with only 10% of labels in the last papers (starting to go beyond)
- Methods coming from NLP
■Content of this presentation
- 3 very different directions
- Using pseudo labelling
- Using Activation Map (like grad-CAM)
- Using depth information
- Leverage frames in videos
Spoiler: there is no self-supervised learning semantic segmentation method that is very convincing…
- High level explanations
- For more details, I provided notes for some papers
- For even more details, please read the original papers
■Pseudo Labeling
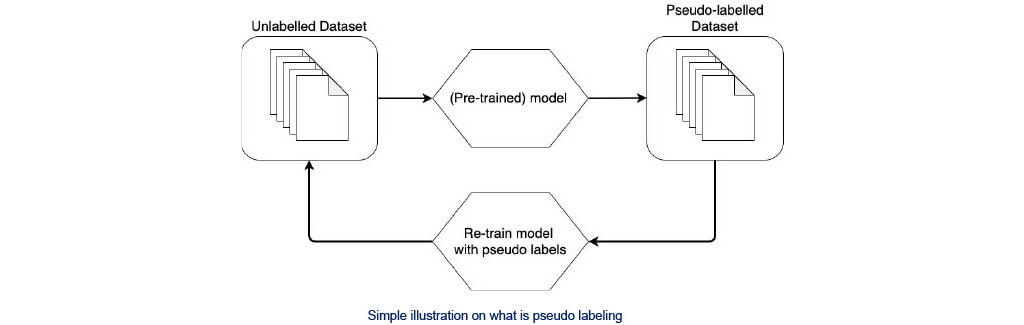
- Usually use softmax to differentiate “strong prediction” to “weak prediction”
- Keep only “strong prediction” as pseudo-labels
- popular research topic
Issue
- Softmax is not the best way since it takes the best score without considering other scores
(which might be promising also)
■Pseudo Labeling: Entropy-guided

My notes
https://arithmer.co.jp/wp-content/uploads/pdf/notes_ESL_Entropy-guided_Self-supervised_Learning_for_Domain_Adaptation_in_Semantic_Segmentation.pdf
Original paper
https://arxiv.org/abs/2006.08658v1
Repo
https://github.com/liyunsheng13/BDL

Model Pre-trained on GTA5 dataset and method used on Cityscapes:
consistently improves the final accuracy but by less than 1% mIoU State-of-the-art for fully supervised learning: 85.1% (IT = image translation)
■Class Activation Map
- Uses gradient information flow to the neurons of a specific CNN layer to identify regions of activation
- Step forward interpretability
- Work from 2017 (last version from last December)

original paper: https://arxiv.org/abs/1610.02391
■Class Activation Map: Equivariant Attention Mechanism
- Need image level annotation (class)
- 3 loss functions combines (ECR, ER and cls)
- a. both CAM outputs should be similar despite Affine transform
- b. But CAM degenerates (converge to a trivial solution) so ECR regularizes the PCM outputs with the original CAM

My notes
https://arithmer.co.jp/wp-content/uploads/pdf/notes_Self-supervised_Equivariant_Attention_Mechanism_for_Weakly_Supervised_Semantic_Segmentation.pdf
Original paper
https://arxiv.org/abs/2004.04581
Repo
https://github.com/YudeWang/SEAM
Main contribution: PCM module
- uses attention to refine the mask from grad-CAM
- attention can capture contextual information

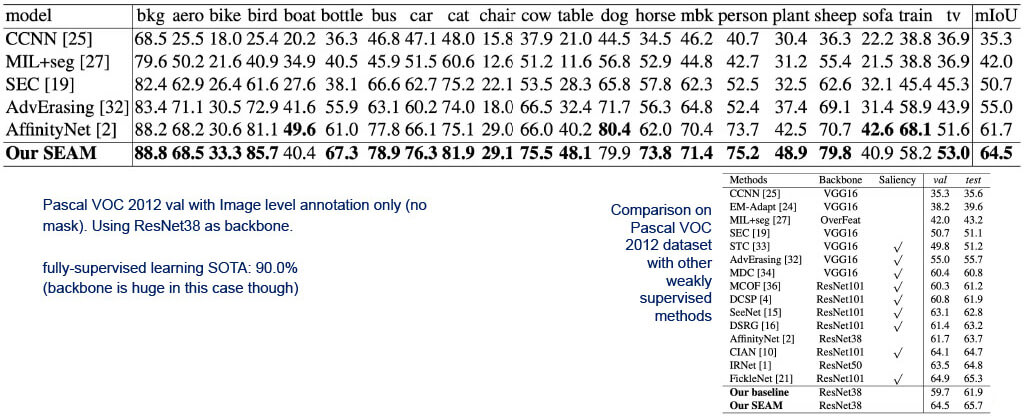
■Class Activation Map: Experiments
■Image Depth Information: HN labels
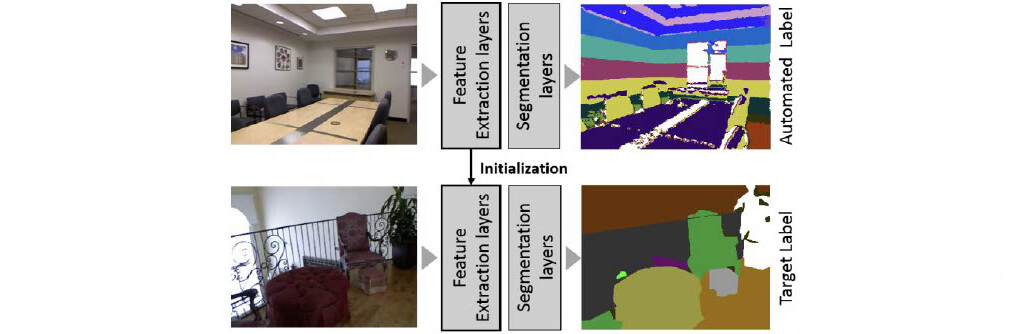
- HN labels generation
- Computing angles and height relative to the floor plane using RGB-D
- Everything is binned to create labels
- Training segmentation model on HN-labels
- Fine-tuning on real dataset
The point is more to show:pretrained HN labels >> pretrained ImageNet
■Image Depth Information: Experiments
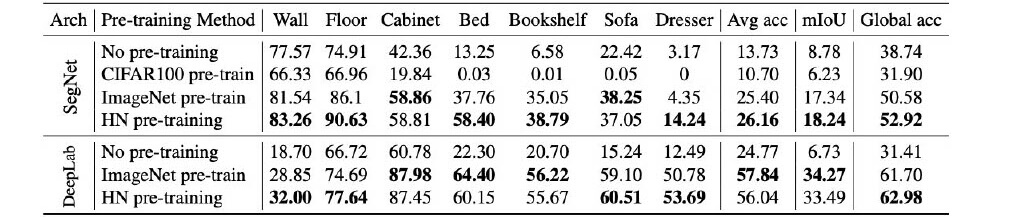
dataset: NUYv2, trained on 50 epochs only. HN labels are from NUYv2. ImageNet is 25x bigger
■How about using videos: Self-supervised Video Object Segmentation

- Learn unsupervised to track similar pixels across frames
- Then when giving an initial mask (on this illustration, in the frame 0), the model can infer the same object for the next frames
Original paper: https://arxiv.org/abs/2006.12480v1
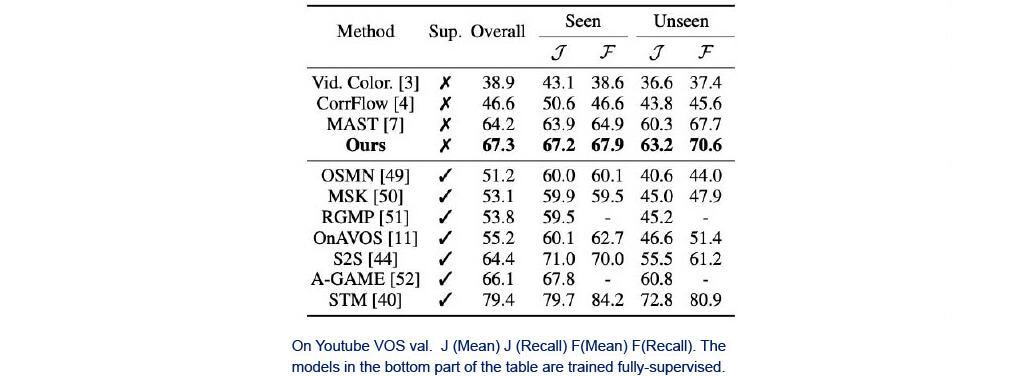
- Learn unsupervised to track similar pixels across frames
- Then when giving an initial mask (on this illustration, in the frame 0), the model can infer the same object for the next frames
Original paper: https://arxiv.org/abs/2006.12480v1