本資料は2021年7月08日に社内共有資料として展開していたものをWEBページ向けにリニューアルした内容になります。
■Contents
Introduction
- Problem to Solve
Dataset
VIBE approach
- Pretrained Model
- Temporal Encoder
- Motion Discriminator
Results
■Problem
- Lack of in-the-wild ground-truth 3D
- Previous work combine indoor 3D datasets with videos having
2D ground-truth or pseudo ground-truth keypoint annotations- Indoor 3D are limited in the number of subjects, range of motion and image complexity
- Poor amount of video labeled with ground-truth 2D pose
- Pseudo-ground-truth 2D labels are not reliable for modeling 3D human motion

※Learning 3D Human Dynamics from Video – https://arxiv.org/pdf/1812.01601.pdf
■Dataset
AMASS dataset for 3D motion capture
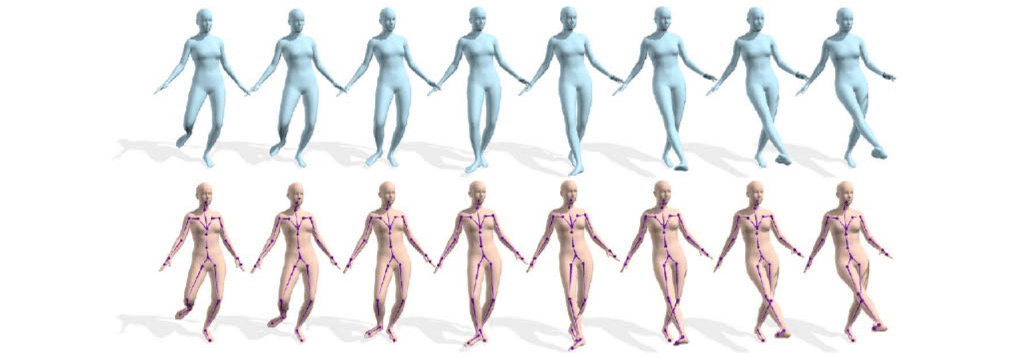
■What is VIBE
“Our key novelty is an adversarial learning framework that leverages AMASS to discriminate between real human motions andthose produced by our temporal pose and shape regression networks. We define a novel temporal network architecture with aself-attention mechanism and show that adversarial training, at the sequence level, produces kinematically plausible motionsequences without in-the-wild ground-truth 3D labels.”
Adversarial learning framework & discriminate, are terms used when referring togenerative adversarial networks. The architecture involves the simultaneous training of two models: the generator and the discriminator. (Thanks enrico for the notes:notion )
Novel temporal network architecture. Since we are analyzing videos, the concept of sequence is implied. VIBE uses a gated recurrent units (GRU) to capture the sequential nature of human motion.
Self-attention mechanism is used to amplify the contribution of distinctive frames.
■Elements VIBE
“Our key novelty is an adversarial learning framework that leverages AMASS to discriminate between real human motions andthose produced by our temporal pose and shape regression networks. We define a novel temporal network architecture with aself-attention mechanism and show that adversarial training, at the sequence level, produces kinematically plausible motionsequences without in-the-wild ground-truth 3D labels.”
Architectures used:
- Yolov3, for detecting the person box
- Resnet50, for feature extraction
- GRU, for sequence encoding
- Self attention, for frame scoring
- GAN, for adversarial training and loss
■VIBE architecture

■Pre-trained model
A sequence of $T$ frames is fed to a convolutional network, $ƒ$, which functions as a feature extractor and outputs a vector $ƒ$i ∈ℝ2048 for each frame

■Temporal encoder output
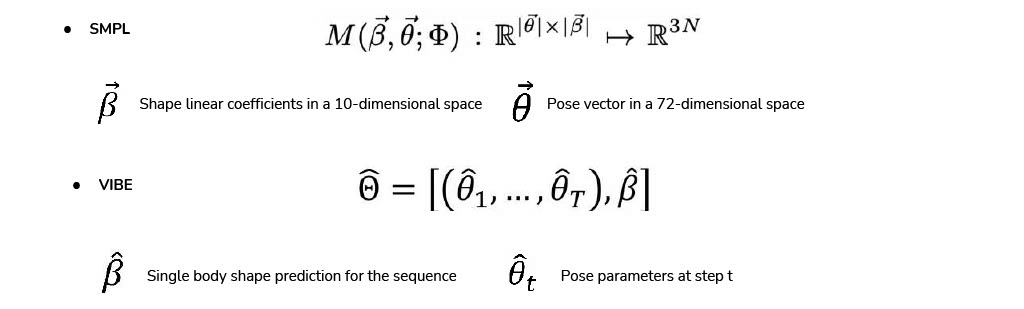
■Temporal encoder

■Motion Discriminator
Enforces the generator to produce feasible real world poses that are aligned with 2D joint locations.

■Results

- Kanazawa et al., End-to-end Recovery of Human Shape and Pose, CVPR 2018
- Kanazawa et al., Learning 3D Human Dynamics from Video, CVPR 2019
- Kolotouros et al., Learning to Reconstruct 3D Human Pose and Shape via Modeling-fitting in the Loop, ICCV 2019